

技术分享:如何设计一个高性能的RDMA系统
2023-08-09 17:45:54
对于分布式数据库产品而言,集群机器之间的网络通信成本是高昂的,为降低这一成本,如何提升网络性能成为了最主要的课题。RDMA技术因为其Low Latency(低时延)和High Throughput(高吞吐)的特点,在对网络性能有极高要求的应用场景中发挥重要作用。
贝格迈思在研发以智能数据库AiSQL为核心的新一代自适应数据智能平台BigInsights中,充分利用RDMA技术加速数据交互,不断优化数据库产品。在研发RDMA系统的过程中,虽然依据不同的需求会有各自的设计理念,但有一些通用的设计理念是任何RDMA中都需要遵循的。本文将深入探讨在设计一个高性能的RDMA系统时,需要遵守哪些通用的设计理念。

RDMA全称为远程直接内存访问(Remote Direct Memory Access),这项技术通过专门的RDMA网卡(RNIC)实现了不同计算机之间的数据直接通过彼此内存和网卡实现交互。
在这一过程中关键是节省了两个资源:1)操作系统;2)CPU。对于操作系统,是避开了复杂和效率偏低的TCP/IP协议栈;对于CPU,是用RNIC来替代其做一些工作,从而降低CPU的负载。
最终达到以下两个目标:1)Low Latency低时延。相比传统的局域网的百个us量级的Round Trip,RDMA可以降低百倍,达到几个us;2)High Throughput高吞吐。2021年发布的RNIC网卡的速度已经达到400Gb/s,是传统的几十倍。
正如这句名言:思考10倍而不是10%的重要性。
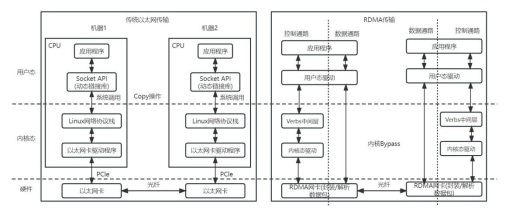
如图1,在这一过程中,本端节点可以像访问本地内存一样,绕过传统以太网的TCP/IP网络协议栈,直接读取和写入远程节点的内存。这种访问方式对远程节点是透明的,而且数据传输时的报文封装解析(如增加Header)和数据校验(如下的CRC)等任务卸载到网卡上完成(如图2),无需软件参与。

RDMA技术使不同计算机之间的数据交互变得高效且直接,大大提升数据传输的速度和效率,这项技术的优点大致可以总结为以下三点:
(1)Zero Copy(零拷贝):传统的Socket通信中CPU需要多次把数据在内存中来回拷贝,而RDMA技术可以直接访问远端已经注册的内存区域(MR,memory region)。
(2)Kernel Bypass(内核旁路):IO(数据)流程可以绕过内核,即在用户层就可以把数据准备好并直接通知硬件准备发送和接收,避免了系统调用(system call)和上下文切换(context switch)的开销。
(3)CPU Offload(CPU卸载):可以在远端节点CPU不参与通信的情况下(当然需要持有访问远程某段内存的“钥匙”)对内存进行读写,也就是将报文封装和解析的任务放到硬件中完成。节省了CPU的开销,让CPU可以做其他更有价值的计算工作。
尽管RDMA技术带来的性能提升受到极大的欢迎,但如何让上层业务充分利用上RDMA带来的性能提升,需要软件工程师根据具体的业务场景需求进行相应的调整和设计,这是一个巨大且复杂的任务。
不存在一个适用于所有场景的RDMA系统,为什么?
因为在实际开发RDMA系统时,你会发现充满了计算机应用的trade-off哲学思想,即不可能又吃到鱼,又可以获得熊掌,试举几例:
(1)如果想和旧系统完全兼容,你就会发现需要重做TCP/IP系统栈的所有工作,比如:错误处理、拥塞处理。随着这些特性的增加,RDMA的性能也会大大降低。
(2)虽然可以采用单边的操作,避免服务端的CPU的全程参与,但这就需要特别的数据结构,从而适应多客户的并发竞争data race,同时也很可能导致通信回合数的增加,从而实际上导致通信成本cost的加大。
但如何仔细设计RDMA系统共有的底层细节对于RDMA系统设计是非常重要的。
为了更好的设计一个高性能的RDMA系统,我们需要对其底层架构有一定的了解。
RNIC属于智能网卡的一类,是一种专门设计用于支持RDMA技术的网卡。它在硬件层面实现RDMA的功能,并提供用于数据传输的高性能网络接口。
下图显示了RNIC的硬件组件细节:
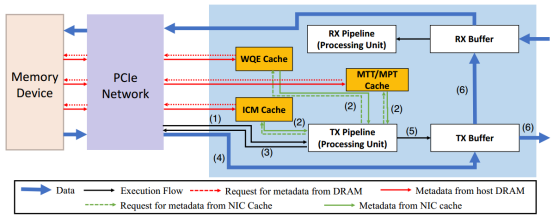

除了数据包缓冲区(TX/RX Buffer),RNIC还具有多个处理单元(PU,Processing Unit)和各种类型的内部高速缓冲区,这些不同的高速缓冲区存储特定类型的数据。如ICM Cache,用来存储QP的上下文(QPC);内存转换表(MTT)内存保护表(MPT);WQE Cache,存储预取的SQ和RQ队列中的WQE。
以一次RDMA write操作为例:
Step 0:CPU通过Doorbell机制(敲门铃,一种通信机制)通知RNIC上的处理单元(PU)有请求待处理。
Step 1:为了获取和处理该请求(WQE),RNIC需要先从各个高速缓冲区中获取相应的元数据(例如:从ICM中获取对应QP的QPC从而定位WQE,检查WQE Cache中是否预存需要的WQE);
Step 2:发生缓存未命中时RNIC通过PCIe总线从主机DRAM中获取相应的元数据(图3中红线)。取得后RNIC处理该WQE,从中获得主机待发送数据的DRAM地址和对端放置数据的地址等相关信息;
Step 3:RNIC发出DMA请求读取主机DRAM中的数据,然后将数据处理成网络包放到TX队列发出。
为了简单起见,未示出对称接收端的操作。
在清楚RDMA整体架构后,现在开始展示RDMA系统的设计指南。为了便于讨论以下优化对CPU和PCIe的影响,我们预先定义任务为:将N个大小为D字节的WQE从CPU传输到NIC。

在介绍各个设计策略之前,为了便于后续理解,我们先对MMIO(Memory-Mapped I/O,内存映射I/O)技术做一个简单的介绍。
MMIO是一种用于进行输入输出操作的技术。它通过将外围设备的寄存器映射到计算机的内存地址空间,使得CPU可以使用和访问这些寄存器就像访问内存一样简单和高效。在MMIO中,设备的控制和数据寄存器被分配一段连续的内存地址,并且可以通过读取和写入这些内存地址来与外部设备进行通信。
策略一:减少CPU的MMIO次数
CPU通过MMIO向NIC发送消息来启动网络操作(这个过程即是Doorbell机制)。这个消息可以是(1)包含新的工作任务(WQE)或者是(2)通过使用最后一个WQE的地址之类的信息来得到新的WQE信息。
如图6,第一种情况下(图6.a),通过64字节的MMIO写组合来传输WQE;第二种情况(图6.b)则是先通过MMIO告知NIC关于WQE的相关信息,然后NIC通过一个或多个DMA操作去相应位置读取WQE。针对这一过程,有两种优化方法减少MMIO次数以提高性能。

Doorbell批处理:如果一个程序向一个QP发布多个WQE,那么它可以为该批使用一个Doorbell MMIO。对于CPU来说,原来需要的MMIO次数为N*D/64次减少到1次。NIC只要付出一个或多个DMA读取相应的WQE。虽然添加了DMA读取,但是对于避免了多个MMIO,这对性能的提高是有帮助的。
WQE收缩:对于使用64字节的MMIO写组合传输WQE时,我们的WQE信息应该尽量是64的倍数,例如WQE从129 B变为128 B时,尽管只是减少了1个字节,但是MMIO次数和PCIe事务都从3个单位变为2个单位。收缩机制包括压缩有效载荷或者将WQE中未使用的头字段用来填充数据。
策略二:减少NIC的DMA次数
减少DMA可以节省NIC的处理能力和PCIe带宽,从而提高RDMA吞吐量。对于RDMA的Recv操作,RDMA除了接收对端传回的有效载荷,还需要通过DMA传输相应的完成队列元素(CQE)。如图7最左侧显示,NIC会分别生成两个单独的DMA来处理Payload和CQE。这两次单独的DMA操作就给了一个优化DMA的空间。这里假设携带的Payload大小为X字节。
Inline RECV(图7中间示意图):如果X很小(0<X<64 B),NIC可以将Payload放入CQE中,之后由驱动程序将其复制到应用程序的指定地址。CPU:拷贝小Payload产生的开销很小。PCIe:从2个DMA变为1个。
Header-only Recv(图7右侧示意图):如果X=0(即数据包中只有数据包头而没有Payload),则NIC不生成Payload的DMA,只将数据包头部的部分信息放入CQE中,应用程序进行相应处理。PCIe:从2个DMA变为1个。

策略三:一个CPU core启用多个NIC处理单元(PU)
利用NIC的并行性是设计高性能所必须的。一个RNIC中存在的多个PU,这些PU通过控制QP来执行相应的任务。并且为了避免跨PU的同步,理想情况下单个QP由同一个PU控制。在这种情况下每个CPU core绑定一个QP。
但是当应用程序处理逻辑简单的事务或者消息处理时间很短的情况下,性能更强的CPU core压倒功能较弱的PU时,CPU的性能被PU的性能限制,造成CPU性能的浪费。在这种情况下,每个CPU核可以使用多个QP来提高CPU效率,这个优化被成为多队列优化。
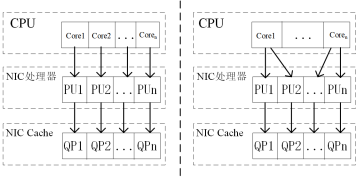
策略四:避免NIC PU之间的竞争
需要跨QP同步的RDMA操作可能会导致PU之间产生竞争,竞争导致的锁争用使得完成这些操作的效率比未争用的操作效率差一个数量级。因此我们应该尽可能的将需求同类资源的WQE放到一个QP上,借助同一QP的操作具有排序依赖性来解决不同QP上的WQE对资源的竞争而导致PU效率的降低。
策略五:避免NIC缓存未命中
RNIC的微架构(图3)显示了RNIC缓存着几种类型的元数据(例如,ICM、MTT/MPT)。如何保持高缓存命中率是非常重要的,因为任何的未命中最终都会转为PCIe的读取。
在相关研究的验证中证实了这一设计指导的重要性:
根据图9显示的结果,通过不断增加QP的数目来提升ICM缓存未命中,发现随着ICM未命中次数的急速提升,在带来高昂的额外PCIe带宽的损耗的同时整个RNIC的吞吐量发生崩溃,性能大幅度降低。
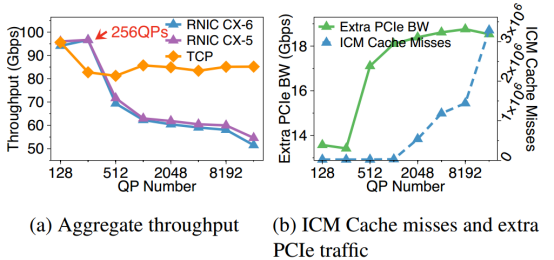
另一项研究通过RDMA的MR控制动词(用来进行内存注册和内存注销)来消耗MTT(图10),发现当MTT缓存未命中率增加到49.1%时,带宽下降到48 Gbps。这两项研究都告诉我们,设计RDMA系统时,NIC缓存命中率指标是不可忽视的重要因素之一。

需要注意的是,以上的设计指南都是针对RDMA系统通用结构的设计策略。对于针对各自场景的RDMA系统,还需要考虑更多方面的因素。
从2016年的100Gb/s到2021年的400Gb/s,RNIC的速度增长了四倍,而在2014年到2019年期间,DRAM的带宽只增长了三倍。随着网络传输速度的加快,研究发现,DRAM的带宽已成为影响RDMA性能的新的瓶颈,而且可以预见的是,这个问题只会加剧而无法消除。
另一方面,对于一个数据中心服务器来说,需要维持数目庞大的连接,这也导致了更多的QP资源的请求。但RNIC上的SRAM缓存是有限的,而NIC缓存未命中对于性能带来的损失是高昂的,因此如何设计一个硬件友好的RDMA系统也是软件工程师需要仔细考虑的问题。
这篇文章我们简要介绍了如何设计一个高性能的RDMA系统,及在设计时需要遵守哪些通用的设计理念。贝格迈思充分利用RDMA技术加速数据交互,在研发以智能数据库AiSQL为核心的新一代自适应数据智能平台BigInsights中,不断优化产品与应用。作为数据智能技术创新引领者,凭借业内领先的各项技术,持续开发多种创新型应用产品,打造数据应用生态。
欢迎各位的持续关注与交流,我们将在未来的技术分享中继续发布更多精彩硬核技术~
产品与服务
解决方案
资源中心
关于我们
 联系方式
联系方式
深圳市南山区粤海街道高新南七道国家工程实验室大楼A1402
0755 - 8670 1822

Copyright © 2022 - 2023 贝格迈思(深圳)技术有限公司 粤ICP备17054434号-1


