

BigInsights高性能分布式数据库架构
2024-01-09 15:31:33
随着5G、物联网和AI技术的全面布局,世界万物互联、智能感知,紧密相关的数据高速产生,快数据继大数据之后成为未来十年显著的时代特征,数据分析正在发生质变。当前,以ChatGPT为代表大语言模型LLM的盛行,更是加速了这种变革。面对更多更快更复杂的实时数据决策分析,传统数据库系统面临着算力不足、多场景融合、多源异构、弹性扩展、高性能、高可靠、高可用、高吞吐量、云原生服务等诸多挑战。快数据密集的数据智能时代,融合人工智能技术的高性能分布式数据库系统将是时代所需。
传统的单机数据库在面对大规模数据量和高并发访问时,往往会面临性能瓶颈和可靠性问题。分布式数据库可以有效地处理大规模复杂的数据,将数据分布存储在多台机器上,实现数据的水平扩展,从而提高了系统的整体性能和容量。同时,分布式数据库可以通过数据复制和容错机制来提高系统的可靠性,即使少量机器发生故障,整个系统仍然可以继续运行,从而避免了单点故障带来的风险。另外,分布式数据库还可以支持跨地域、跨数据中心的部署,提高了系统的可用性和灾备能力。因此,分布式数据库可以有效解决单点故障和性能瓶颈的问题,提高系统的可靠性、可用性和扩展性。
BigInsights是贝格迈思面向快数据实时分析所需研发的新一代高性能分布式数据库,满足从强一致核心交易到复杂计算及分析的企业级实时业务需求,针对高速高并发的实时处理及分析应用场景具有其高效适用性。相较于传统分布数据库,BigInsights践行了一条不同的技术路线:
1)BigInsights融合新型硬件技术革新,打造自适应处理器的异构智能计算平台,通过软硬一体化创新设计的分布式架构实现高性能和高可用;
2)BigInsights分布式内存驱动架构,通过高速网络和端到端的总线协议,在分布式内存中实现HTAP和NewSQL统一融合的完全分布式事务处理机制,真正做到数据强一致性和系统扩展性的统一;
3)BigInsights行列混合存储和可查询压缩技术,实现高效数据查询和海量数据存储能力;
4)BigInsights云原生NewSQL分布式架构,使数据库更具弹性扩展和多模态数据适用性;
5)BigInsights实现以DRAM和存储级内存SCM为中心,兼容NVMe-oF SSD的软件定义多级数据存储架构,实现冷热分离的多级数据存储系统,充分发挥DRAM、SCM和NVMe-oF SSD的不同特性,实现高效数据存储。
6)通过向量引擎及 SIMD向量并行能力为大规模数据计算提供底层并行和并发计算的基础。
BigInsights作为一个分布式数据库系统,具有很强的容量和性能。它可以很好地支持海量数据的高并发处理与访问,满足了企业对于可靠和高效的数据存储与处理能力的需求。同时,BigInsights将多模态计算统融于统一的计算框架,以应对数十亿级以及关系、图、文档等多模态的分析查询需求,基于自适应的异步并行框架和事务调度机制大大提高任务调度效率。
本文将从几个重要方面来介绍BigInsights是如何同时实现高性能和高可用的。包括分布式架构设计、动态扩缩容机制、负载均衡策略、存储引擎优化、缓存设计、支持新的硬件等技术,以及其内部采用的高性能事务处理方法等。
NewSQL分布式架构
BigInsights将企业级关系数据库功能与NewSQL云原生架构的水平可扩展性和弹性伸缩相结合,系统采用Share-Nothing架构以节点为单元进行弹性伸缩,基于MPP+SMP并发模式充分地利用NODE的集成资源,融合了NoSQL和SQL的优点,具有高性能、高可用性和高扩展性,满足用户的按需使用和简单易用需求,利用“极致弹性”满足数据智能时代下企业业务的快速发展需求。BigInsights高效分布式事务基于Google Spanner架构设计,主副本之间写入操作的强一致性通过Raft协议实现,集群级的分布式ACID事务使用混合逻辑时钟(hybrid logical clocks)实现,支持SSI(Snapshot serializable isolation)隔离级别。读操作默认保证强一致性,但可以动态选择从Follower读和副本读。
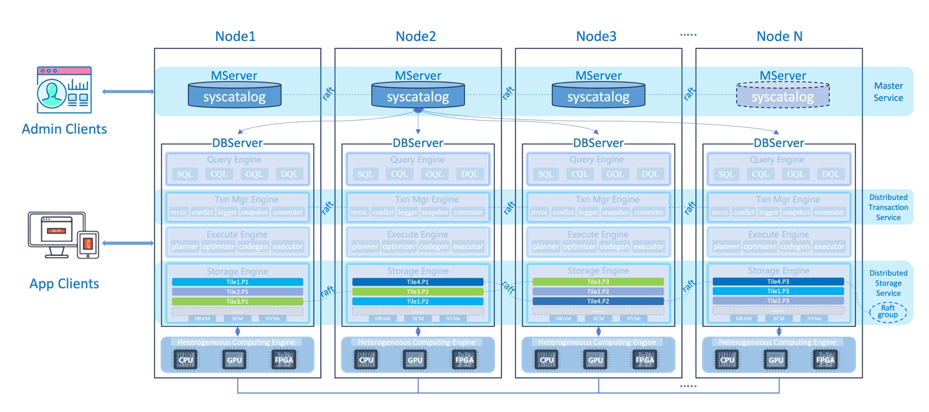
BigInsights云原生分布式系统架构(参照图一)以Node节点为基本扩展单元,每个节点主要有两个组件MServer和DBServer。其中,MServer负责系统元数据管理,包括基本存储单元 Tile的位置信息、表结构、安全信息、配置管理等信息,MServer本身依靠 Raft 实现高可用,并可单独扩展。DBServer是BigInsights的数据库核心组件,负责数据库相关的分布式事务和数据处理,从逻辑上主要分为四层:查询引擎Query Engine、事务引擎Transaction Engine、执行引擎Execute Engine和存储引擎Storage Engine,这些引擎从逻辑上都位于DBServer进程中,共享DBServer的进程空间。
查询引擎Query Engine主要支持 SQL和CQL两种 API。其中SQL API完全兼容PostgreSQL语法; CQL API兼容 Cassandra 的NoSQL语法,对应于文档数据库的存储模型。
事务引擎Transaction Engine主要负责分布式事务处理。BigInsights通过MVCC 结合快照隔离的事务实现,与基于锁定和两阶段提交的方法相比,它在避免冲突方面具有优势,支持任意规模的跨多行、多分片和多个节点完全分布式ACID事务,实现了透明且可扩展的事务处理,遵守严格的响应时间要求:
· 将更新的可见性与原子提交分离,实现事务横向扩展。避免了组件之间任何形式的复杂且耗时的协调,例如两阶段提交协议。相反,事务可以快速并行提交,而不会影响一致性。
· 分解和分配各种相对独立的事务任务分配到事务管理器的不同独立组件,并单独扩展它们,例如本地事务管理器(mvcc)、冲突管理器(conflict)、记录器、快照服务器和提交定序器等。
· 尽可能引入异步和消息批处理。异步使得大部分混乱处理都在事务范围之外,批处理可以减少消息总数。
执行引擎Execute Engine是完全并行分布式的,实现了查询间并行性和查询内并行性,特别是支持运算符内并行性,并且可以具有任意数量的实例。为了横向扩展 OLTP 工作负载,本地执行引擎实例负责处理本地数据副本查询的子集。
存储引擎Storage Engine主要基于LSM-Tree实现以tile分片方式数据高效存储管理。BigInsights的最小数据分片单位为tile,是一种将table 进行垂直和水平切分实现行列混合存储的数据切分单元。每个tile数据分片对应一个 Raft Group,可配置分布在多个节点上,以此保证高可用性,相应的元数据由MServer管理。Tile式数据分片可以有效支持OLTP和OLAP混合事务能力,并且很好的发掘数据关联聚合能力,提升数据本地联合操作性能。

BigInsights基于Tile实现行列混合存储,表Table被按行或列进行聚簇式分片,类似于BigTable的列族column family进行相关列聚合存储。参照图二,Person表包含PersonID、Name、Address、BirthDate、Gender等一系例相关person信息的列,其中Name和Address是强相关列,因此聚合为personal_data列族;BirthDate和Gender属于IO相似列,因此BirthDate和Gender聚合为demographic列族。从而,person表可以按照列族和行进行划分成不同tile单元。Tile单元内数据组织基于行列混合存储模式,按PAX格式进行持久化数据存储。Tile数据存储可以有效的融合行存储和列存储的各自优势,有效支持OLTP和OLAP混合的HTAP事务处理能力。很显然,针对OLTP任务可以选择面向行存储的Tile,例如图二中的TileX;相应地OLAP任务,会选择倾向于列存的Tile,如图二中的Tile1、Tile2以及TileN。结合AiSQL的自调优机制,这种Tile可以挖掘或学习行列数据间的关联性,自动实现数据表中基于相关行列数据的调整和切分,实现更具用户应用场景的最优数据分片方法。
PAX提供了一种基于page的行列混合存储机制。在 page 里面使用了一种 mini page 的方式,将 record 切到到不同的 mini page 里面。假设有 n 个 attributes,PAX 就会将 page 分成 n 个 mini pages,然后将第一个 attribute 的放在第一个 mini page 上面,第二个放在第二个 mini page,以此类推。PAX 的格式其实是行存储和列存储的一种折中,当要依据某一列进行 scan 的时候,我们可以方便的在 mini page 里面顺序扫描,充分利用 cache。而对于需要访问多 attributes 得到最终 tuple 的时候,我们也仅仅是需要在同一个 page 里面的 mini page 之间读取相关的数据。
可见,基于PAX的混合存储可以在一个数据库中既有行存储结构,又有列存储结构,两种存储结构结合使用以提升系统的整体性能,重要的是,它是一个 Cache 友好高效的行列混存模式。Google Spanner首次采用PAX行列混合数据结构Ressi,用来支持 OLTP 和 OLAP。
BigInsights有效的基于Tile模式进行数据分片机制,每张表被分成很多个 tiles,tile是数据分布的最小单元,通过在节点间搬运 tile以及 tile的分裂与合并,就可以实现几乎无上限的 scale out。每个 tile有多个副本,形成一个 Raft Group,通过 Raft 协议保证数据的高可用和持久性,Group Leader 负责处理所有的写入负载,其他 Follower 作为备份,数据分布模式参照图三。MServer 节点会负责协调 tile的搬运、分裂等操作,保证集群的负载均衡,这些操作是直接基于 Raft Group 实现。

分布式数据库的关键要素之一是数据如何在不同的数据存储节点之间分布。BigInsights基于Tile的数据分片模式很好的解决了有效支持HTAP的数据组织模式。但是,如何均匀的分布Tile的数据划分方式至关重要。BigInsights提供基于范围分区的主索引哈希(Partition Hashing Primary Index(PHPI))(参考图四)方式进行数据划分:
· 键值范围分区:基于分区列进行范围划分,均匀的把数据分配到各个主机。
· 哈希映射分区:哈希是一种非常简单的分区方案,并且具有非常擅长跨数据存储平衡数据的优点。系统将从密钥计算哈希值,并根据哈希值的模数分配数据。有效的一致性哈希算法可以有效的将数据分配到相应的节点。哈希的缺点是对于扫描系统必须在所有数据存储中进行扫描,因为数据可以存储在任何数据存储中,与键范围分区相比,扫描需要更多的资源。
· 二维分区:二维分区是一种自动分区模式,通常是结合在前述分区模式一起使用。首先,需要定义一个随时间变化的参数和一个标准,使系统自动对数据进行分区以获得最佳资源。特别是如何有效的随着时间变化,系统运行自动发现不同列数据间的关联性,从而进行列族聚簇,实现不同tile的数据划分模式。BigInsights不仅允许二维分区,还允许多维分区。

BigInsights基于范围分区的主索引哈希数据分片方法可以很好的为系统扩缩和自动数据平衡提供了算法保证。特别是,基于主索引范围划分索引为负载范围查询提供了高效的数据访问保证;基于一致性哈希散列和虚拟节点聚合算法,可以有效的实现数据的均匀散列到所有数据节点。该方法的另一大优点在于系统扩所容导致的数据迁移影响的节点较少,主要针对相邻范围内的节点,结合raft机制,基本可以实现自动化高效系统扩所容和负载均衡能力。这一点在NewSQL分布式数据库(如CockroachDB、ScyllaDB、Cansandra等)和P2P分布式哈希表DHT得到了很好的验证,对分布式系统自动数据均衡有很大作用。
Raft协议能够轻松实现动态成员资格更改。当节点被删除时,只需要重新运行受影响分片的Raft领导者选举,并由MServer主导重新创建复制副本以实现完全复制。当节点被添加到集群后,MServer会根据每个DBServer上持有的分片数和分片领导数自动进行负载平衡,将分片移动到新加入的节点上。这种方式实现了快速的横向扩展和缩减,提升了读写负载的性能。
如图五所示,我们将新节点4添加到具有三个节点和四个分片的群集时究竟会发生什么。节点1有两个领导者,Tile1-Leader和Tile4-Leader。

· 将向集群添加新节点Node 4。
· MServerLeader察觉到集群的变化并启动负载均衡操作。这涉及到领导者(例如Tile4-Leader)离开节点1。
· 为了实现完全的负载平衡,⼀些追随者也会从节点2和节点3移动到节点4。需要注意的是,所有的移动都是以公平的方式进行的,没有⼀个现有节点承担填充新节点的负担,集群中的所有节点都按照公平的份额计算,因此集群永远不会受到压⼒。
· 图六展示了最终的完全负载平衡的集群,每个节点都有⼀个领导者和三个追随者。

BigInsights的架构设计实现了快速的横向扩容和缩容,确保了集群的高可用性,并提升了读写性能。它通过将读写负载均衡到其他节点上,充分利⽤整个集群的硬件资源。这种设计使得BigInsights能够灵活地适应不同的⼯作负载,并实现⾼效的数据处理能力。
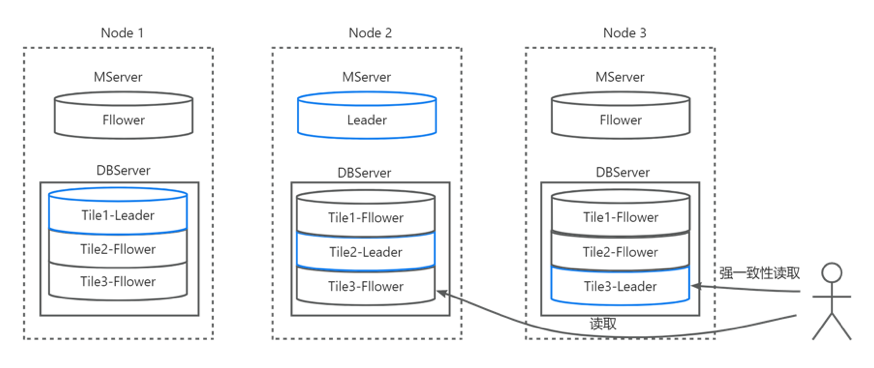
鉴于在写⼊时已经完成了确保一致性的重要任务,BigInsights的Raft实现确保读取请求可以以极低的延迟提供服务,⽽无需使用任何仲裁。此外,它允许应⽤程序客户端选择从Leader读取(用于强⼀致性读取)或从Follower读取(⽤于时间线⼀致性读取)。 BigInsights甚⾄允许从异步更新的集群中取读副本,这些副本不参与写⼊路径。从 Follower中读取副本可以显著提高系统的吞吐量,因为Follower⽐Leader多,⽽且如果Leader恰好位于不同地区,甚⾄可以减少延迟。
我们知道,Cache是实现有限内存对磁盘热数据的高效缓存,是提高读性能的最重要数据库组件。LRU(Least Recently Used,最近最少使用)是一种常见的缓存淘汰算法。LRU算法的基本思想是根据数据的访问历史记录来淘汰最近最少使用的数据,以便为新的数据腾出空间。
LRU算法适用于需要根据访问模式来淘汰数据的场景,例如缓存系统和页面置换算法。但数据库的Scan操作是不利于这个LRU算法。当DBScan时,一时间会产生大量的数据并进入到链表的热头,虽然这些Scan数据如果只被用到一次,最终会通过链表冷尾驱逐出去,但是,它因为消耗内存特别大,导致一些热数据被不当的驱逐出链表,从而降低了读性能。
大家都知道RocksDB API接口既支持点查找Lookup,也支持范围查找Scan。早期的RocksDB的缓存只支持block形式缓存,即缓存的单位是block(block大小可设,最小是4KB,但一般是几十KB)。这就存在一个浪费,比如:我们需要的是点查Lookup,访问一个4KB的某个key/value,其key/value大小之和假设只要100字节,那么为了这么一个100字节的kv,我们却至少需要缓存4KB大小的一个block,即浪费率是 (1 - 100/4000) * 100% = 98%。RocksDB在后续版本加入了row cache,针对key/value的更细粒度的缓存。因为存在范围查询,所以,block cache和row cache都提供,让程序员根据应用类型work load来选用,或者组合使用。
这就带来了新的问题,内存大小是一定的,block cache和 row cache应该设置比例是多少。假如当前初始设置在比例是1:1已经是最优选择。但是随着时间推移,用户在work load发生了变化,点查和scan查询的比例发生了变化,这样就不能最有效利用缓存。
还有另一个问题,一个数据分片持有一个RocksDB实例。一个节点持有多个分片,假如每个分片都独自管理自己的cache。那么就会因为有的分片数据冷,有的分片数据热。这样冷的分片的cache就没有得到有效利用。
BigInsights采用智能统一cache管理,根据当前work load负载情况,动态调整row cache和block cache大小比例。同时统一管理调度cache,防止出现cache孤岛出现。根据访问情况把cache分为多个等级,防止scan 引起不应该的hot key被淘汰。
图八是BigInsights优后的缓存算法和RocksDB传统LRU算法效果对比:

另外,缓存管理机制和B+ Tree在内存的负载上有很多性能瓶颈,比如将Page ID转换成内存指针的Hash Table和它对应的全局Latch,访问B+ Tree的每个内存节点时需要获取Latch等。为了达到更好的性能,像H-Store、Hekaton、HANA、HyPer、或 Silo 这样的内存数据库都摒弃了Buffer Manager的设计,把数据和索引直接存储在内存中,通过内存指针而不是Page ID来高效的访问这些数据。
BigInsights通过去中心化的Pointer Swizzling和页替换机制实现了工作在SSD上的缓存管理,通过这个缓存管理和乐观锁等关键技术实现了高性能B+ Tree,让BigInsights既能支持 大容量的工作负载,又能提供和内存数据库一样的性能表现。
BigInsights实现以DRAM和SCM内存为中心,兼容NVMe-oF SSD的软件定义多级数据存储架构,可以实现数据的冷热分离的多级数据存储系统,充分发挥DRAM、SCM和NVMe-oF SSD的不同特性。例如将热数据和索引存于DRAM、温数据和OLAP模式数据列式结构持久化于SCM以及冷数据和LOG日志数据持久化于SSD。
此外,BigInsights存储引擎是基于LSM-tree的低成本、高性能存储引擎,其组成部分包括热数据层和冷数据层。热数据层存储在内存中,包括活跃内存表、固化内存表和缓存,而冷数据层则存储在持久化磁盘上,采用多层次结构。活跃内存表具有高插入性能,而固化内存表则会逐渐转储至持久化存储介质。
从内存中转存而来的Immemtable中的记录会按照数据块的格式被插入L0中。当L0被填满后,其中的部分数据块会被选中,通过异步的合并操作(Compaction)和L1中的数据块合并,并从L0中移出。同理,L1中的数据块最终会被合并到L2中。BigInsights存储引擎采用将L0层的数据保存在NVMe设备上,L1层及以下的数据保存在传统存储介质上SSD/HHD。

对于OLTP型业务,由于对访问延迟非常敏感,云厂商通常采用本地SSD或ESSD云盘作为存储介质。然而,对于流水型业务(如交易物流、即时通信等),大部分数据在生成后访问频次逐渐降低,甚至不再被访问。将这些冷数据与热数据一样存储在NVMe、SSD等高速存储介质上,会显著降低整体性价比。BigInsights存储引擎通过分析负载的访问特征,实现精准的冷热数据分离,并结合混合存储架构自动归档冷数据,为用户提供极致的性价比。
另外,BigInsights设计了一种基于NVMe-oF SSD快存储融合B-Tree和LSM-Tree混合架构的键值存储引擎,采用快慢存储混合的存储数据存储架构,全面加速数据读写性能。一方面,在NVMe-oF SSD快存储上采用SPDK技术构建了一个用户态文件系统BMFS,BMFS中的文件是无序的SLAB文件。在NVMe-oF SSD快存储上使用无序的SLAB文件存储键值对象,在内存中构建B-Tree索引来快速查找键值对象,在NVMe-oF SSD快存储上不考虑压缩操作,而在慢存储(例如Disk)上采用LSM树,并使用SST文件存储键值数据。另一方面,引入一种基于读感知的冷热分层压缩算法(即上述冷热存储分层存储策略)。该算法将数据在快慢存储之间进行压缩,通过读感知追踪数据的冷热程度,冷数据从快存储降级压缩到慢存储,热数据从慢存储升级压缩到快存储,最终实现热数据被固定在快存储上。这种基于NVMe-oF SSD快存储融合B-Tree和LSM-Tree混合架构的键值存储引擎设计,显著提升系统读写能力(实验显示至少5倍左右的性能提升),降低慢存储上的写放大问题,延长慢存储(如Flash)的使用寿命。
BigInsights通过软硬一体化创新设计,针对现代CPU、GPU和FPGA的不同并行数据分析能力,构建统一的异构自适应计算框架,从底层硬件充分激发异构处理器协同并行计算能力,全面突破冯.诺依曼体系架构固有的内存墙性能瓶颈,全面提升数据库系统性能。
BigInsights的事务处理机制可以在满足 ACID 特性要求的情况下,结合多核处理器与内存的硬件特性,实现极高的事务处理性能。增、删、改、查数据库中的记录是事务处理所需要的基础能力,我们可以将这一系列操作视为写路径和读路径。
1. 写路径
如图九所示,为了在 DRAM 内存掉电易失的情况下保证数据库中存储数据的持久化,对数据库记录的所有修改操作都要先记录在WAL预写日志中并存储在NVMe快速存储介质上。然后再存入内存的活跃内存表中。然后再通过两段式 Read/ Write Phase 和 Commit Phase 的衔接配合来保障一个事务对记录所做的修改符合 ACID 特性,并在完成提交后对其他事务和查询可见。活跃内存表存满后被转为固化内存表,稍后再被 Flush 落盘完成持久化。
2. 读路径
读路径。如图十所示,BigInsights执行引擎中的查询操作按照活跃和固化内存表(Memtables/Immutable)、行级缓存(Row Cache)、块级缓存(Block Cache)和磁盘的顺序依次查询数据。内存表采用的多版本跳跃链表结构可以降低热点记录查询的开销。行级缓存和块级缓存可以分别缓存磁盘中的热数据记录或记录块,可以减少磁盘访问的布隆过滤器(Bloom Filters)和相应索引块(Index Block)。

3. 高效能的事务处理
如图十一 BigInsights执行引擎为处理每一条分布式事务设计了两阶段的并行事务处理流水线,具体分为准备阶段和提交阶段。准备阶段完成所有所需的查询和计算操作,然后将所需要进行的修改暂存入事务缓冲区中。
在提交阶段,多个准备线程负责将事务中要写的内容写入无锁的任务队列(Task Queues)中。随后,多阶段流水作业消费线程会处理相应的任务,包括写WAL日志、日志落盘、写入RocksDB内存表,最终完成事务提交。不同阶段的任务通过事务缓冲区交接数据,实现了并行执行,同时处理不同数据。这种交叠执行时间的方式提高了每个线程的指令缓存命中率,最终提高了系统的吞吐率。在提交阶段中,每个任务队列由一个后台线程负责管理,而任务队列的数量受系统中可用I/O带宽等硬件条件的限制。

在图十二所示的分阶段事务流水线中,针对每个阶段的特性,我们分别优化了其并行粒度。具体而言,第一阶段的写日志缓存(收集一个任务队列中所有写入内容的相关日志)和第二阶段的日志落盘由于存在数据依赖,因此由单一线程串行完成;第三级的写内存表则由多个线程并发完成对内存表的写入;第四级的提交负责释放相应的资源(如所持有的锁和内存空间等),使所有修改可见,由多个线程并行完成。所有的写入线程采取主动拉取工作的方式,从任意级别中获取所需执行的任务。这种设计允许我们分配更多的线程来处理带宽高、延迟低的访问内存的工作,同时适用较少的线程完成带宽相对较低、延迟相对较高的写入磁盘工作,从而提高了硬件资源的利用率。同时,各个阶段内的任务相同,可以批量处理任务,大大提高了任务的处理能力。

综上所述,BigInsights高性能分布式数据库,通过合理的架构设计和技术选型,可以实现高性能、高可靠性和高扩展性的分布式数据库系统,为企业提供可靠、高效的数据存储和处理能力,助力企业实现数据驱动的业务创新和发展。
BigInsights 通过先进的架构提供高性能、高可用性、可扩展性和容错能力,同时通过 BSQL 和 BCQL API 提供简单的接口易于开发和使用。 为了评估BigInsights真实能力并展示其处理实际工作负载的潜力,Benchmark基准测试是有效的途径。基准测试是评估系统在特定工作负载下的性能和功能的过程,以深入了解其可扩展性、弹性和整体效率。 此过程涉及使用标准化工作负载模拟现实世界的使用场景,以了解系统的执行、扩展和从故障中恢复的情况。 评估数据库处理各种工作负载的能力主要有 TPC-C、TPC-H和 TPC-DS 基准测试,它们代表了分布式数据库不同方面的性能,本文展示了BigInsights TPC-C 的测试情况, 其他测试结果可以参考贝格迈思官网文档。
TPC 是一系列事务处理和数据库基准测试的规范。其中TPC-C(Transaction Processing Performance Council)是针对 OLTP 的基准测试模型。TPC-C 测试模型给基准测试提供了一种统一的测试标准,可以大体观察出数据库服务稳定性、性能以及系统性能等一系列问题。对数据库展开 TPC-C 基准性能测试,一方面可以衡量数据库的性能,另一方面可以衡量采用不同硬件软件系统的性价比,也是被业内广泛应用并关注的一种测试模型。
测试结果
数据库服务器节点类型:8vCPU RAM64GB

通过这个实验,我们证实了BigInsights具有线性横向扩展的特性,证明了9个数据节点的性能比3数据节点的性能提高了3倍,这使得 BigInsights能够通过确定系统规模来处理任何事务工作负载。另外,系统的事务数量与TPC-C基准以及响应时间相关。使用 BigInsights,平均响应时间(12分钟内)与部署中的仓库和数据节点的数量无关。基于TPC-C 基准测试 12分钟的平均响应时间,BigInsights的响应时间保持在11ms左右。相较于其他创新型分布式数据库系统(如CockroachDB、YugabyteDB等),BigInsights在相应时间方面具有数量级(即至少10倍)性能提升的明显优势。
产品与服务
解决方案
资源中心
关于我们
 联系方式
联系方式
深圳市南山区粤海街道高新南七道国家工程实验室大楼A1402
0755 - 8670 1822

Copyright © 2022 - 2023 贝格迈思(深圳)技术有限公司 粤ICP备17054434号-1


